
Football Analytics - Home
Football is a sport that has a very big fanbase around the world. This project focuses on scraping football data from Transfermarkt using Python and analyzing the data to get insights. The project is still in progress and will be updated regularly.
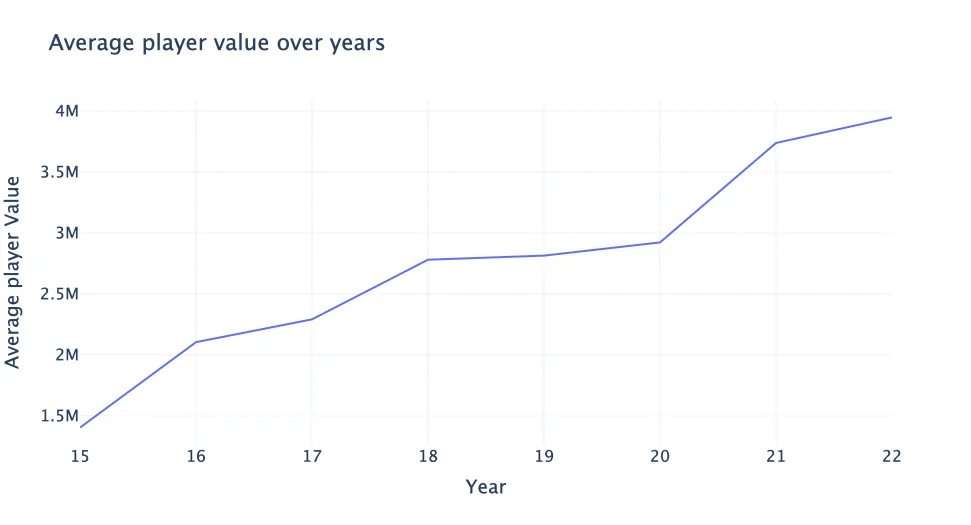
Average player FIFA value across years (15 represents 2015)
Just like the stock market, the transfer market in football is a constantly fluctuating landscape, with players’ values rising and falling based on performance and a wide range of other factors. This is the collective growth of players’ prices over time. One reason for this inflation is the huge increase in clubs’ revenues over the last decade. It’s clearly visible that the average price grew consistently over this period, suggesting inflation in FIFA player value over the last decade. Images by author. As demonstrated above, the entire market is susceptible to macro trends.
The impact of this data extends beyond mere statistics; it provides a foundation for predictive models and machine learning applications. Analyzing the data can help identify patterns in player performance over time and predict future trends, such as potential increases or decreases in market value. Furthermore, such analysis can be applied to real-time applications, including fantasy football, sports betting, and player scouting. The dataset can even serve as a tool to assess the economic effects of player transfers between clubs or the impact of player performance on the success of a team. Given the increasing reliance on data-driven decision-making in sports, this dataset opens the door for numerous applications in the sports industry, providing both valuable insights and actionable strategies.
In this study, we implement a machine learning pipeline to classify the value of football players based on performance metrics, contract details, and demographic attributes. The dataset undergoes preprocessing, including categorical encoding for non-numeric features and standardization of numerical variables to ensure consistency. To address class imbalance, we apply a balanced sampling strategy, ensuring equal representation of both valuable and non-valuable players. Furthermore, we employ statistical techniques to detect and remove outliers, improving the quality and reliability of the dataset before model training.
Following data preparation, we split the dataset into training and test sets and apply machine learning models for classification. Feature scaling is performed using standardization to optimize model performance, while label encoding ensures categorical variables are effectively incorporated into the learning process. Various classification models are evaluated to determine the most effective approach for predicting player value. The pipeline is designed to enhance model robustness and generalizability, ensuring that insights derived from the data are both accurate and applicable in real-world football analytics.
Models
More details and code are available on GitHub